


作为最近在旧金山举行的 Mistral 黑客马拉松的一部分,来自 Phospho 和 Quivr 的开发人员为大型语言模型 ( LLM ) 创建了一个名为 LLM Colosseum 的独特基准, 用于测试他们在复古视频游戏《街头霸王 III》上的能力。
它的工作原理是这样的:语言模型接收屏幕的文本描述,并实时决定移动的方向以及使用什么技术。所有后续动作都取决于模型本身和敌人之前的动作,以及特殊动作的生命值和能量。
根据LLM Colosseum官方排行榜,8种不同语言模型之间进行了342场对决,GPT-3.5 Turbo无条件领先,评分为1776.11分。这明显高于 GPT-4,GPT-4 的分数范围为 1400 到 1585 分,具体取决于具体版本。
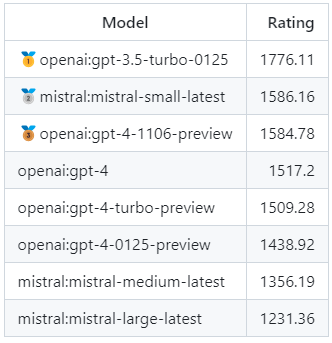
开发人员 Nicholas Ulyanov 解释了更简单模型的突然优势,他说 LLM 在此类测试中的成功取决于速度和智力的平衡。 “GPT-3.5 Turbo 很好地结合了速度和智能。 GPT-4 更大、更智能,但速度慢得多,”开发人员说道。
在 Amazon Web Services 开发人员 Banjo Obayomi 进行的另一项《街头霸王 III》实验 中 ,模型在 Amazon Bedrock 平台上进行竞争。在本次比赛中,Claude模型获得了前四名,展现出了最好的成绩。
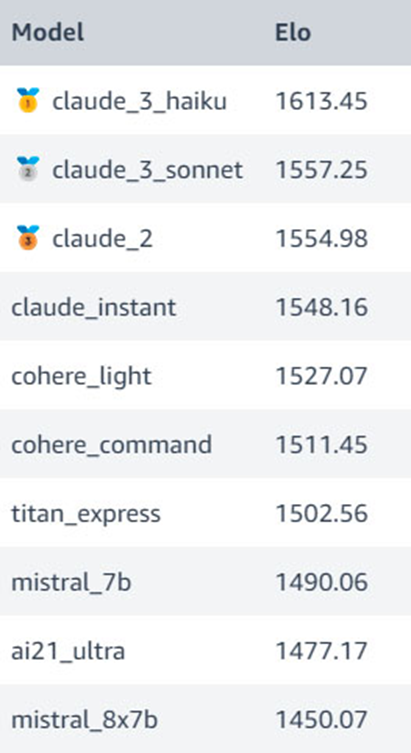
乌里扬诺夫表示,人工智能模型还无法与职业选手竞争,目前只能与儿童或老年对手竞争。
乌里扬诺夫还批评了评估模型的传统方法,认为它们无法充分展示人工智能的真实能力。他认为像 LLM Colosseum 这样的项目展示了神经网络的真正能力:“这个项目表明 LLM 可以变得如此智能、快速和多功能,以至于它们可以在任何需要即时决策的地方使用。”
文章原文链接:https://www.anquanke.com/post/id/295632

